Juliana Jenny Kolb
Home > Simulados on-line > Questões de Concursos > Tecnologia da Informação (TI) > Questões Banco de Dados
Teste 3: Banco de Dados
Questões extraídas de concursos públicos e/ou provas de certificação. Cada teste apresenta no máximo 30 questões.
DDL – Linguagem de Definição de Dados, comandos: </br> Para ler mais sobre o assunto, acesse: DDL ( ) Primeira Forma Normal (1FN): Eliminação de domínios multivalorados “Uma tabela só estará na 1FN se nenhum dos seus atributos tem domínio multivalorado” Nesta forma os atributos precisam ser atômicos, o que significa que as tabelas não podem ter valores repetidos e nem atributos possuindo mais de um valor. Exemplo: CLIENTE = {ID ENDEREÇO TELEFONES}. Porém, uma pessoa poderá ter mais de um número de telefone, sendo assim o atributo “TELEFONES” é multivalorado. Para normalizar, é necessário: Para ler mais sobre o assunto, acesse: Modelagem Relacional ( ) DDL – Linguagem de Definição de Dados, comandos: </br> Para ler mais sobre o assunto, acesse: DDL ( ) O comando SELECT permite ao usuário especificar uma consulta (“query“) como uma descrição do resultado desejado. Utilizar uma instrução SELECT na cláusula WHERE de outra instrução SELECT, recebe o nome de subquery. Para ler mais sobre o assunto, acesse: DQL ( )Results


#1. (FGV – IBGE/2016) João foi incumbido de rever um lote de consultas SQL. Como ainda é iniciante nesse assunto, João solicitou ajuda ao colega que lhe pareceu ser o mais experiente, e recebeu as seguintes recomendações gerais: I. use a cláusula DISTINCT somente quando estritamente necessária; II. dê preferência às junções externas (LEFT, RIGHT, OUTER) em relação às internas (INNER); III. use subconsultas escalares no comando SELECT, tais como “SELECT x,y,(SELECT …) z …” sempre que possível. Sobre essas recomendações, é correto afirmar que:
#2. (FURB – ISSBLU/2015) A PL/SQL é uma extensão da linguagem padrão SQL para o Sistema Gerenciador de Banco de Dados Oracle. Através da PL/SQL, é possível desenvolver trechos de programas os quais são armazenados, compilados e executados no próprio servidor Oracle. Considere o seguinte trecho de código:
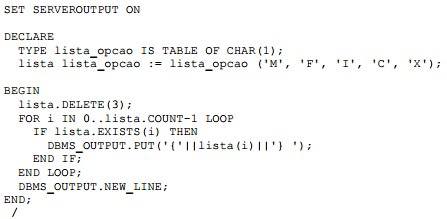 O resultado da execução desse código na saída DBMS em uma sessão do Oracle 11g é:
O resultado da execução desse código na saída DBMS em uma sessão do Oracle 11g é: #3. (CESPE – TCU/2015) Em um banco de dados estruturado de acordo com o modelo relacional, todos os elementos dos dados são colocados em tabelas bidimensionais, organizados em linhas e colunas, o que simplifica o acesso e a manipulação dos dados. Operações matematicamente conhecidas como de produto cartesiano, de seleção e de projeção também apoiam a manipulação de dados aderentes ao modelo relacional.
#4. (CESPE – TCU/2015) Considere as seguintes configurações de servidores de banco de dados (SBD): I O controle de concorrência do servidor X foi configurado para o tipo bloqueio de modo múltiplo. II Especificamente na tabela T do servidor X, foram criados, em dois campos distintos, dois índices (IdxA e IdxB) contendo apenas um campo para cada um: o primeiro, IdxA, do tipo primário, e o segundo, IdxB, do tipo secundário, em um campo não chave. III Dois servidores foram configurados para trabalhar de forma distribuída do tipo SBDF (sistemas de banco de dados federado), com intuito primordial de garantir mais disponibilidade, no caso de falha de um dos servidores. IV O servidor Z foi configurado com um sistema do tipo orientado a objeto. Caso a finalidade do acesso seja a leitura, o modo descrito na configuração I permitirá que várias transações acessem o mesmo item. Logo, esse modo é menos restritivo que o bloqueio binário, no qual, no máximo, uma transação pode manter um bloqueio em determinado item.
#5. (FGV – IBGE/2016) No SQL Server 2012, a finalidade de um banco de dados do tipo snapshot é:
#6. (FGV – IBGE/2016) No SQL Server 2012, tabelas que possuem índices do tipo clustered equivalem no Oracle, do ponto de vista da organização dos dados, às tabelas do tipo:
#7. (FGV – IBGE/2016) João faz a manutenção de uma aplicação que acessa um banco de dados Oracle. Entretanto, essa aplicação é utilizada por vários clientes, cada um deles com suas próprias instalações e usuários, o que eventualmente causa erros na localização das tabelas e outros objetos. Num cenário como esse, uma boa prática é referenciar os nomes das tabelas por meio de:
#8. (FGV – IBGE/2016) Com relação ao sistema de replicação, disponível para o PostgreSQL, denominado Slony-I, analise as afirmativas a seguir: I. Permite a replicação em cascata, master→slave→slave. II. Permite que um componente slave seja empregado no papel de master em caso de falha deste. III. É um componente nativo, que implica pequeno esforço de instalação e configuração. É correto concluir que:
#9. (FGV – IBGE/2016) No MYSQL, os formatos de replicação correspondem aos formatos utilizados para registrar eventos nos logs. O formato conhecido como “statement-based binary logging”, utilizado desde as versões mais antigas, tem problemas com certas cláusulas e funções utilizadas nos comandos geradores dos eventos. Nesse contexto, analise as construções que podem aparecer num comando a ser replicado. I. a cláusula LIMIT sem ORDER BY para comandos como UPDATE, DELETE, REPLACE; II. a função RAND(); III. o comando TRUNCATE TABLE; IV. funções definidas pelo usuário (UDF) que sejam determinísticas. Comprometem a correta execução da replicação, no formato descrito, somente o que é citado em:
#10. (FGV – IBGE/2016) Várias implementações SQL adotam uma lógica de três estados para tratamento de expressões lógicas que envolvem valores nulos. Considerando que “T”, “F” e “?” denotam, respectivamente, os valores lógicos true, false e desconhecido, analise as seguintes expressões lógicas: T or ? F or ? T and ? F and ? not ? O valor lógico dessas expressões, na ordem, é:
#11. (FGV – IBGE/2016) João escreveu a consulta SQL a seguir, executou-a corretamente e obteve um resultado contendo 100 linhas, além da linha de títulos. select curso, nome from aluno, curso where aluno.codcurso = curso.codcurso order by curso, nome As tabelas aluno e curso possuem, respectivamente, 120 e 12 linhas. No banco há ainda outras duas tabelas, pauta e disciplina, com 200 e 5 registros, respectivamente. Nessas condições, o número de linhas, além da linha de títulos, produzidas pelo comando select curso, nome from aluno, curso, disciplina, pauta where aluno.codcurso = curso.codcurso order by curso, nome seria:
#12. (FGV – IBGE/2016) Analise os comandos Oracle RMAN para extração de backups a seguir: I. BACKUP INCREMENTAL LEVEL 0 DATABASE; II. BACKUP INCREMENTAL LEVEL 1 CUMULATIVE DATABASE; III. BACKUP INCREMENTAL LEVEL 1 DATABASE; É correto afirmar que o comando:
#13. (UNICENTRO – UNICENTRO/2016) Considere que o seguinte script SQL será usado para criar a estrutura de um banco de dados.
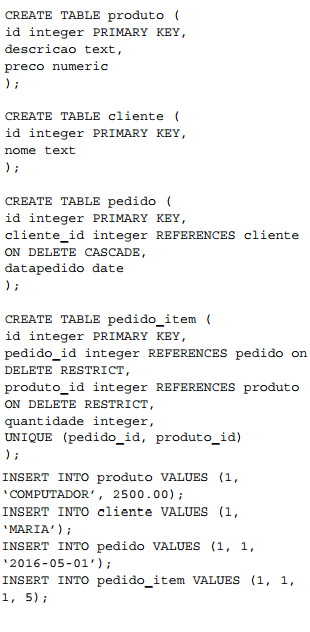 Dados os comandos: A) “DELETE FROM cliente WHERE id = 1” B) “DELETE FROM produto WHERE id = 1” C) “DELETE FROM pedido_item WHERE id = 1” E as sentenças: I. O comando A apaga o cliente, o pedido e o item do pedido. II. O comando A apaga o cliente e o pedido, mas não o item do pedido. III. O comando B apaga o produto e o item do pedido. IV. O comando A e o comando B não apagam registros. V. O comando C não apaga registro. Considerando a integridade referencial existente entre as tabelas, a(s)sentença(s) correta(s) é/são:
Dados os comandos: A) “DELETE FROM cliente WHERE id = 1” B) “DELETE FROM produto WHERE id = 1” C) “DELETE FROM pedido_item WHERE id = 1” E as sentenças: I. O comando A apaga o cliente, o pedido e o item do pedido. II. O comando A apaga o cliente e o pedido, mas não o item do pedido. III. O comando B apaga o produto e o item do pedido. IV. O comando A e o comando B não apagam registros. V. O comando C não apaga registro. Considerando a integridade referencial existente entre as tabelas, a(s)sentença(s) correta(s) é/são: #14. (UNICENTRO – UNICENTRO/2016) Sobre os parâmetros de configuração do PostgreSQL: I. Uma das formas de definir parâmetros é editar o arquivo postgresql.conf II. A alteração dos parâmetros nos arquivos de configuração são automaticamente entendidas pelo servidor PostgreSQL, que as replica a todas as conexões. III. As alterações dos parâmetros no arquivo de configuração são ignoradas até que ocorra uma releitura do mesmo. Uma das formas de forçar a releitura é reiniciando o processo/serviço do banco de dados. IV. Vários parâmetros podem ser alterados em tempo de execução com o comando SET, mantendo o valor apenas para sessão corrente. A alternativa que contém as respostas corretas é:
#15. (UNICENTRO – UNICENTRO/2016) A extensão pgsql do PHP (5.0 ou superior) provê funções para se trabalhar com o banco PostgreSQL. Sobre essas funções é correto afirmar:
#16. (CETRO – AMAZUL/2015) A linguagem SQL é dividida em subconjuntos de acordo com as operações que se deseja efetuar sobre um banco de dados. Um desses subconjuntos é a DDL. Assinale a alternativa que apresenta apenas comandos de DDL.
?
A correção aparecerá no rodapé da questão, caso você erre ou não selecione uma opção de resposta.
#17. (CETRO – AMAZUL/2015) Na normalização, a primeira Forma Normal deve garantir que
?
A correção aparecerá no rodapé da questão, caso você erre ou não selecione uma opção de resposta.
#18. (CETRO – AMAZUL/2015) Restrições de Integridade são usadas para garantir a consistência e a exatidão dos dados. Uma delas especifica quais valores podem admitir. Assinale a alternativa que apresenta o nome dessa restrição.
#19. (CETRO – AMAZUL/2015) Assinale a alternativa correta quanto aos Atributos em um Sistema de Gerenciamento de Banco de Dados.
#20. (FUNCAB – CREA-AC/2016) Uma forma de estabelecer segurança em sistemas gerenciadores de bancos de dados (SGBD) de modo a se conceder privilégios de acesso de grupos ou usuários do SGBD para objetos específicos de um banco de dados, como, por exemplo, tabelas ou visões, é através de:
#21. (CESPE – TCU/2015) Na configuração IV, o SBD agrega o conceito de encapsulamento ao definir o comportamento de um tipo de objeto com base nas operações que podem ser aplicadas externamente a objetos desse padrão.
#22. (INTEGRI BRASIL – Câmara de Votorantim-SP/2016) A normalização de dados é um processo que segue uma série de passos para se projetar um banco de dados, é responsável por fazer que tais dados sejam armazenados de forma consistente e eficiente. Os passos de um processo de normalização de dados reduzem a redundância e inconsistências das informações. Analise a descrição do passo de normalização de dados a seguir: “Elimina grupos repetidos, colocando-os cada um em uma tabela segregada, relacionando-os com uma Primary Key (chave primária) ou Foreign Key (chave estrangeira)”. A passo descrito anteriormente refere-se a:
#23. (INTEGRI BRASIL – Câmara de Votorantim-SP/2016) “É uma técnica de desenvolvimento de sistemas onde as tabelas do banco de dados são representadas através de classes e os registros dessas tabelas são como instâncias das classes correspondentes”. Esta é uma definição para:
#24. Os comandos de definição de dados (DDL – Data Definition Language) fazem parte da linguagem SQL. Dentre os comandos a seguir, qual é um comando DDL?
?
A correção aparecerá no rodapé da questão, caso você erre ou não selecione uma opção de resposta.
#25. (INTEGRI BRASIL – Câmara de Votorantim-SP/2016) Utilizar uma instrução SELECT na cláusula WHERE de outra instrução SELECT, recebe o nome de:
?
A correção aparecerá no rodapé da questão, caso você erre ou não selecione uma opção de resposta.
#26. (INTEGRI BRASIL – Câmara de Votorantim-SP/2016) Em SQL, são procedimentos executados de forma automática sempre quando ocorre uma certa ação do usuário, por exemplo, uma inserção em uma tabela. É uma definição para:
#27. (INTEGRI BRASIL – Câmara de Votorantim-SP/2016) Qual o comando SQL que concede privilégios e autoriza usuários de um banco de dados a acessar informações ou modificar tabelas?
#28. (INTEGRI BRASIL – Câmara de Votorantim-SP/2016) A cláusula WHERE da linguagem SQL é utilizada para especificar as condições que devem reunir os registros que serão selecionados. Ela é parte opcional da(s) instrução(ões):
#29. (FGV – IBGE/2016) No PostGreSQL, a linguagem PL/pgSQL pode ser utilizada para definir procedures que são executadas como triggers, quando várias “special variables” são criadas, no escopo do bloco mais externo, e tornam-se disponíveis para uso no código da procedure. Nesse contexto, analise as seguintes afirmativas sobre algumas dessas variáveis e o funcionamento de triggers no PostgreSQL: I. A variável NEW contém um valor booleano que indica se o registro objeto do trigger está sendo incluído (true) ou não (false). II. A variável NEW contém os campos de um registro que está sendo incluído (insert) ou alterado (update). III. A variável TG_OP contém uma string que determina o nome da operação que desencadeou o trigger (insert, update, etc.). IV. Na declaração de um trigger, as opções FOR EACH ROW e FOR EACH STATEMENT são equivalentes, tendo sido mantidas apenas para efeito de compatibilidade com versões anteriores. Está correto somente o que se afirma em:
