
Home > Engenharia de Software > Sumário > Gestão de Configuração de Software

Controle de Versões
Controle de versões combina procedimentos e ferramentas para gerir diferentes versões de objetos de configuração.
Um sistema de controle de versões deve apresentar as características:
- banco de dados de projeto (repositório);
- capacidade de gestão de versões (armazenamento de versões anteriores);
- facilidade para construção de versões;
- acompanhamento de bugs.
Sobre Controle de Versão
O que é controle de versão, e por que você deve se importar? O controle de versão é um sistema que registra as mudanças feitas em um arquivo ou um conjunto de arquivos ao longo do tempo de forma que você possa recuperar versões específicas. Mesmo que os exemplos desse livro mostrem arquivos de código fonte sob controle de versão, você pode usá-lo com praticamente qualquer tipo de arquivo em um computador.
Se você é um designer gráfico ou um web designer e quer manter todas as versões de uma imagem ou layout (o que você certamente gostaria), usar um Sistema de Controle de Versão (Version Control System ou VCS) é uma decisão sábia. Ele permite reverter arquivos para um estado anterior, reverter um projeto inteiro para um estado anterior, comparar mudanças feitas ao decorrer do tempo, ver quem foi o último a modificar algo que pode estar causando problemas, quem introduziu um bug e quando, e muito mais. Usar um VCS normalmente significa que se você estragou algo ou perdeu arquivos, poderá facilmente reavê-los. Além disso, você pode controlar tudo sem maiores esforços.
Sistemas de Controle de Versão Locais
O método preferido de controle de versão por muitas pessoas é copiar arquivos em outro diretório (talvez um diretório com data e hora, se forem espertos). Esta abordagem é muito comum por ser tão simples, mas é também muito suscetível a erros. É fácil esquecer em qual diretório você está e gravar acidentalmente no arquivo errado ou sobrescrever arquivos sem querer.
Para lidar com esse problema, alguns programadores desenvolveram há muito tempo VCSs locais que armazenavam todas as alterações dos arquivos sob controle de revisão (ver Figura 1-1).
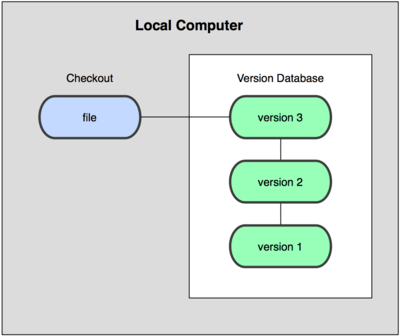
Figura 1-1. Diagrama de controle de versão local.
Uma das ferramentas de VCS mais populares foi um sistema chamado rcs, que ainda é distribuído em muitos computadores até hoje. Até o popular Mac OS X inclui o comando rcs quando se instala o kit de ferramentas para desenvolvedores. Basicamente, essa ferramenta mantém conjuntos de patches (ou seja, as diferenças entre os arquivos) entre cada mudança em um formato especial; a partir daí qualquer arquivo em qualquer ponto na linha do tempo pode ser recriado ao juntar-se todos os patches.
Sistemas de Controle de Versão Centralizados
Outro grande problema que as pessoas encontram estava na necessidade de trabalhar em conjunto com outros desenvolvedores, que usam outros sistemas. Para lidar com isso, foram desenvolvidos Sistemas de Controle de Versão Centralizados (Centralized Version Control System ou CVCS). Esses sistemas, como por exemplo o CVS, Subversion e Perforce, possuem um único servidor central que contém todos os arquivos versionados e vários clientes que podem resgatar (check out) os arquivos do servidor. Por muitos anos, esse foi o modelo padrão para controle de versão.
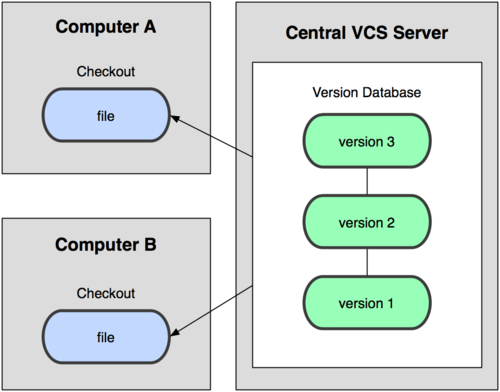
Figura 1-2. Diagrama de Controle de Versão Centralizado.
Tal arranjo oferece muitas vantagens, especialmente sobre VCSs locais. Por exemplo, todo mundo pode ter conhecimento razoável sobre o que os outros desenvolvedores estão fazendo no projeto. Administradores têm controle específico sobre quem faz o quê; sem falar que é bem mais fácil administrar um CVCS do que lidar com bancos de dados locais em cada cliente.
Entretanto, esse arranjo também possui grandes desvantagens. O mais óbvio é que o servidor central é um ponto único de falha. Se o servidor ficar fora do ar por uma hora, ninguém pode trabalhar em conjunto ou salvar novas versões dos arquivos durante esse período. Se o disco do servidor do banco de dados for corrompido e não existir um backup adequado, perde-se tudo — todo o histórico de mudanças no projeto, exceto pelas únicas cópias que os desenvolvedores possuem em suas máquinas locais. VCSs locais também sofrem desse problema — sempre que se tem o histórico em um único local, corre-se o risco de perder tudo.
Sistemas de Controle de Versão Distribuídos
É aí que surgem os Sistemas de Controle de Versão Distribuídos (Distributed Version Control System ou DVCS). Em um DVCS (tais como Git, Mercurial, Bazaar ou Darcs), os clientes não apenas fazem cópias das últimas versões dos arquivos: eles são cópias completas do repositório. Assim, se um servidor falha, qualquer um dos repositórios dos clientes pode ser copiado de volta para o servidor para restaurá-lo. Cada checkout (resgate) é na prática um backup completo de todos os dados (veja Figura 1-3).
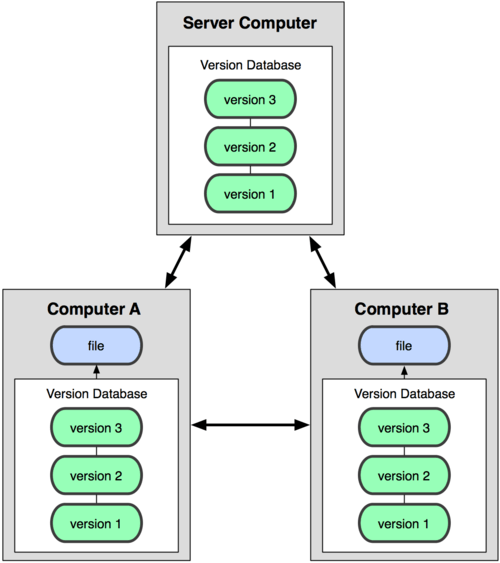
Figura 1-3. Diagrama de Controle de Versão Distribuído.
Além disso, muitos desses sistemas lidam muito bem com o aspecto de ter vários repositórios remotos com os quais eles podem colaborar, permitindo que você trabalhe em conjunto com diferentes grupos de pessoas, de diversas maneiras, simultaneamente no mesmo projeto. Isso permite que você estabeleça diferentes tipos de workflow (fluxo de trabalho) que não são possíveis em sistemas centralizados, como por exemplo o uso de modelos hierárquicos.
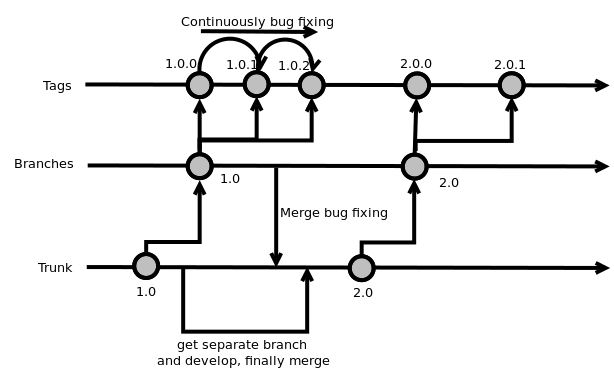
Trunk, Branch e Tag
Trunk
É o principal tronco de desenvolvimento, seguindo desde o início do projeto até o presente. É nele que o projeto deve se basear sempre. Normalmente é gerido por um desenvolvedor e recebe merges após aprovação de alguém que é responsável pelo projeto. Não faz sentido existir mais do que um trunk.
Branch
É um galho da árvore de desenvolvimento. É uma cópia do código derivado de um certo ponto do trunk que é utilizado para a aplicação de mudanças no código, preservando a integridade do código no trunk. Se as mudanças funcionam de acordo com o planejado, elas geralmente são mescladas de volta para o tronco principal (trunk). É muito usado para experimentos e para desenvolvimentos paralelos.
É usado o tempo todo. Apesar do trunk ser o repositório principal, todo o desenvolvimento costuma ser feito em cima dos galhos locais ou remotos dependendo do fluxo de trabalho escolhido. É comum chamarmos o branch de versão de trabalho. É um rascunho que pode ser guardado para depois, para jogar fora, permanecer privado para um desenvolvedor ou grupo específico sem entrar no projeto.
Onde existem muitos branches pode criar dificuldades para executar o merge, por isso cada vez mais sistemas de controle de versão distribuídos estão fazendo cada vez mais sucesso em projetos muito ativos e principalmente descentralizados. Por isso é comum não incentivar branches descontroladamente quando se usa SVN.
Em muitos casos o branch funciona como uma futura versão.
Tag
É um marcador de um estado do código em um determinado momento. É um ponto no tempo no trunk ou em um branch que você deseja preservar. As duas principais razões para a preservação seriam:
este é um grande lançamento do software, se alfa, beta, RC ou RTM;
este é o ponto mais estável do software antes de aplicar revisões importantes sobre o trunk.
Não é comum trabalhar em cima de uma tag. É criado um marco que pode ser acessado facilmente. Quando encontrar um bug em versão antiga que precisa de uma solução, é fácil criar um branch em cima dele para fazer o conserto.
O que costuma diferenciar tag de branch é justamente a estabilidade do conteúdo. Você não deve deveria mexer em um repositório tag. Ele se diferencia do trunk por ser algo secundário e quase sempre está no passado.
Como usar
Em projetos de código aberto, os branches que não são aceitos no trunk pelos participantes do projeto podem se tornar as bases para forks, por exemplo.
Fork costuma ser um repositório completamente novo, com seu próprio trunk mas que é derivado de um repositório original (mesmo que este já seja um fork). É uma árvore de desenvolvimento nova mas criada de outra árvore. É comum haver comunicação entre estas árvores e em alguns casos até bidirecionalmente. Nestes casos o trunk de um acaba funcionando como branch de outro. Desta forma percebe-se que estes conceitos são bem abstratos.
Os conceitos apresentados são recomendações. Nada impede dos desenvolvedores fazerem de uma forma totalmente diferente se for mais adequado para o projeto. Esta é uma forma consagrada e provavelmente mais adequada para a maioria dos casos. Quanto menor a equipe e mais centralizado é o processo, menos vantagens existem em usar este esquema. E de fato é comum, mesmo em projetos open source pequenos, que o desenvolvimento acabe sendo feito essencialmente em cima do trunk e forks costumam funcionar como branches do projeto.
É preciso experimentar alguns fluxos de trabalho diferentes e escolher o que traz maior benefício para seu projeto.
Referência Bibliográfica
PRESSMAN, Roger S. Engenharia de Software, Sexta Edição. Editora MCGrawHill: Porto Alegre, 2010.
https://git-scm.com/book/pt-br/v1/Primeiros-passos-Sobre-Controle-de-Vers%C3%A3o